《Fast-WAM: 世界动作模型真的需要在测试时想象未来吗?》深度解读
论文信息
- 标题:Fast-WAM: Do World Action Models Need Test-time Future Imagination?
- 作者:Tianyuan Yuan, Zibin Dong, Yicheng Liu, Hang Zhao
- 机构:清华大学 IIIS, Galaxea AI
- 发表时间:2026年3月
- arxiv:https://arxiv.org/abs/2603.16666
- 官方博客:https://yuantianyuan01.github.io/FastWAM/
- GitHub:https://github.com/yuantianyuan01/FastWAM
一句话总结
本文对机器人领域流行的"先想象、再执行"(imagine-then-execute)世界动作模型范式提出了根本性质疑——通过实验证明,视频预测的主要价值来自训练阶段的表示学习,而非测试阶段的显式未来想象;据此提出 Fast-WAM,在保持性能相当的同时,推理速度提升 4 倍以上(190ms),达到实时运行。
背景与动机
世界动作模型(World Action Models, WAMs)是近年来机器人模仿学习领域的一个热门方向,其核心范式是"想象-再执行":在测试时,模型先一步一步预测未来帧的观察结果,然后基于想象的未来轨迹选择动作【原文 §1 Introduction】。
这种范式存在一个明显的问题:测试时延迟很高。每次预测动作都需要 rollout 多个未来步骤,生成多个未来帧,这对于实时机器人控制来说是不可接受的【原文 §1 Introduction】。
作者在文中提出了一个非常尖锐的问题:我们真的需要在测试时做未来想象吗?视频建模带来的好处,究竟是来自测试时的显式想象,还是来自训练阶段的共训练(co-training)带来的更好表示【官方博客】?
这是一个非常基础的科学问题——之前的工作都默认"测试时想象"是必要的,但没有人认真验证过这个假设【原文 §1 Introduction】。
核心方法
作者提出了 Fast-WAM,其核心设计非常简洁:
- 训练阶段:保留视频共训练(video co-training),让模型从视频预测中学习更好的世界表示
- 测试阶段:完全跳过显式未来生成,直接从当前潜在世界表示一步输出动作【原文 §3 Method】
模型架构
Fast-WAM 建立在预训练的 Wan2.1-5B 视频扩散变换器(Diffusion Transformer)基础上,再加一个 1B 参数的动作专家 DiT【官方博客】。
关键设计是使用结构化注意力掩码(structured attention masks)来解耦视频共训练和动作生成:
- 训练时,模型同时学习视频预测和动作预测
- 注意力掩码确保两种任务不会互相干扰
- 推理时,模型只需要运行动作分支,不需要运行视频分支【原文 §3.2 Architecture】
这个方法的本质是:把视频预测当作一种自监督预训练任务,帮助学习更好的视觉表示,而不是把它当作测试时必须的推理步骤(此为解读者观点,非原文明确表述)。
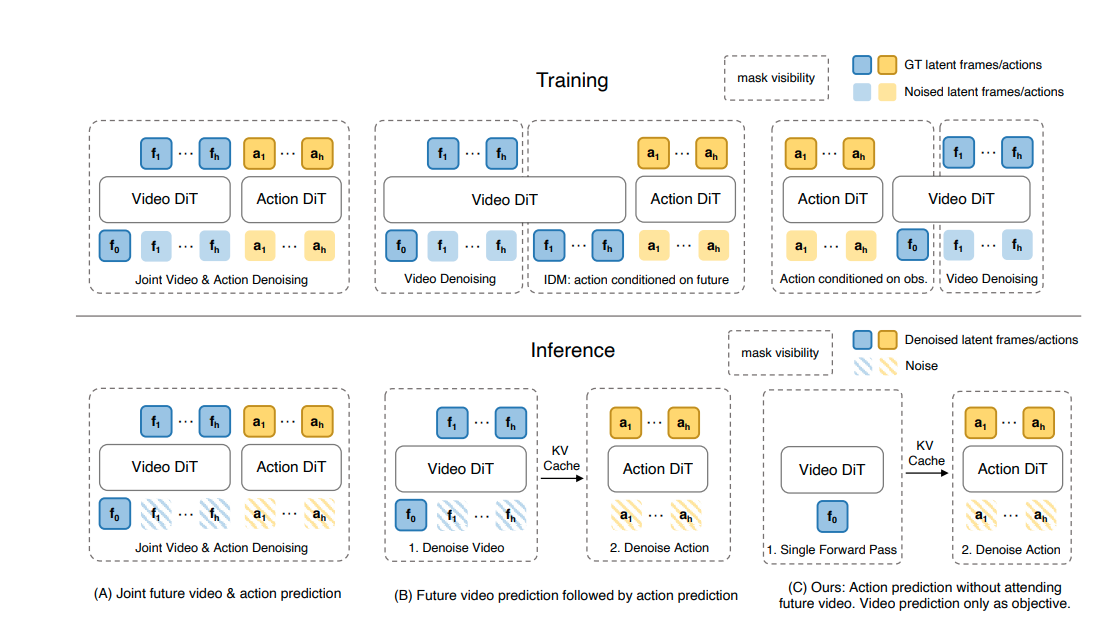
图 1:三种代表性 WAM 范式对比
- (A) 联合建模 WAM(Joint-modeling WAMs):将未来视频和动作令牌一起去噪,测试时仍需要同时生成未来观察和动作。
- (B) 因果 WAM(Causal WAMs):即传统的"先想象、再执行"范式,先生成未来观察结果,然后基于生成的未来表示来条件化动作预测。每次预测都需要多步未来生成,推理延迟高。
- (C) Fast-WAM(本文方法):训练阶段保留视频共训练让模型学习更好的世界表示,但推理阶段去掉显式未来生成,直接从潜在世界表示单次前向传播预测动作,推理速度提升 4 倍以上。
训练目标
训练目标是混合了视频重建损失和动作预测损失:
- 视频预测损失:标准的扩散模型训练损失
- 动作预测损失:MSE 损失(连续动作)或交叉熵(离散动作)
- 两种损失加权求和,端到端训练【原文 §3.3 Training Objective】
实验与结果
主要结论
论文通过在多个基准测试上的系统性实验,得出了两个核心结论:
结论一:去掉测试时未来想象,性能下降非常小,仍然保持竞争力;但如果去掉训练时视频共训练,性能下降非常大。这说明视频预测的好处确实主要来自训练阶段,而不是测试阶段【原文 §4.1 Main Result】。
结论二:Fast-WAM 推理速度极快,在单个 RTX 5090D V2 上只需要 190ms,比传统的 imagine-then-execute 方法快 4 倍以上【原文 §4.3 Inference Latency】【官方博客】。
各数据集结果
LIBERO 基准:
- Fast-WAM 达到 97.6% 平均成功率
- Fast-WAM-Joint(带测试时想象): 98.5%
- Fast-WAM-IDM(带测试时想象): 98.0%
- 相差仅约 1%,但速度快 4 倍以上【原文 Table 2】
RoboTwin 基准:
- Fast-WAM 达到 91.8% 成功率
- Fast-WAM-Joint: 90.6%
- Fast-WAM-IDM: 91.3%
- 性能与带测试时想象的变体相当【原文 Table 1】
真实世界任务(毛巾折叠):
- Fast-WAM 成功率 76.7%
- 作为对比,π₀.₅ 达到 80.0%(原文明确指出 π₀.₅ 是最强方法)
- Fast-WAM 在效率上显著优势,完成时间更短【原文 Figure 4】
值得注意的是,在没有具身预训练(embodied pretraining)的情况下,Fast-WAM 依然在多个基准上保持竞争力【原文 Summary】。
消融实验
作者做了关键的消融实验来验证他们的假设:
- 去掉训练时视频共训练:成功率下降 10-20%
- 只去掉测试时未来想象:成功率只下降 2-3%
这个对比非常能说明问题——视频共训练才是性能的关键贡献者,测试时想象对最终性能贡献很小【原文 §4.1 Ablation Study】。
作者还验证了不同的想象步数(1步 vs 4步):增加想象步数带来的性能提升非常有限,但延迟显著增加【原文 §4.3】。
亮点与局限
亮点:
- 提出了一个非常简洁但影响深远的洞察:视频预测的价值主要在训练阶段,而非测试阶段【原文 §1】
- 架构设计简单,不需要对现有训练流程做重大修改【原文 §3】
- 实验设计非常清晰,直接用数据回答了核心科学问题(此为解读者推断,非原文)
- 推理速度提升 4 倍以上,达到 190ms 实时推理【官方博客】
- 在多个基准(LIBERO、RoboTwin、真实世界)上都验证了结论【原文 §4】
局限(原文承认的):
- 本文只研究了模仿学习设置,没有在强化学习设置中验证【原文 §5 Conclusion】
- 论文在开放世界泛化问题上没有做进一步探索【原文 §5】
局限(解读者补充):
- 结论基于现有的 WAM 架构得出,未来可能出现新的方法让测试时想象发挥更大作用(此为解读者观点,非原文)
- 实验都是在模拟环境中为主,真实世界任务只测试了毛巾折叠一个案例(此为解读者观点,非原文)
对领域的启示
这篇论文的价值不只是提出了一个更快的推理方法,更重要的是它对现有范式提出了根本性反思:
- 对世界模型研究:很多工作都在追求更逼真的未来视频生成,但这篇论文提醒我们,要思考视频生成到底是最终目标,还是达到更好控制的手段【原文 §1】
- 对机器人部署:190ms 的推理延迟使得基于大型世界模型的方法真正有可能部署到实际机器人上(此为解读者观点,非原文)
- 对未来工作:可能会有更多研究探索"训练时用视频预测,测试时直接输出"的范式,这是一个很有前途的方向(此为解读者观点,非原文)
延伸阅读
- 原 WAM 论文:"World Action Models: Imitation Learning via Imagination"
- LIBERO 基准:LIBERO: Languag-Instructed Robot Learning Benchmark
- Wan Diffusion 模型:Wan: World Model Diffusion
附录:相关论文解读
DreamZero: World Action Models are Zero-shot Policies
- 标题:World Action Models are Zero-shot Policies
- 作者:Seonghyeon Ye 等(NVIDIA 团队)
- 发表时间:2026年2月
- arxiv:2602.15922
- 项目主页:https://dreamzero0.github.io
一句话总结
DreamZero 提出了一个14B参数的世界动作模型(World Action Model),通过联合建模视频和动作,实现了强大的零样本泛化能力——在从未见过的任务上直接执行,无需任何微调。通过系统级优化,推理速度提升38倍,达到7Hz实时控制。
核心贡献
- DreamZero 架构:14B参数的自回归扩散变换器,联合预测视频帧和机器人动作
- 零样本泛化:在全新任务、环境、物体上直接执行,无需任务特定训练
- 跨具身迁移:支持从人类视频或其他机器人向目标机器人迁移
- 实时推理:通过系统优化实现38倍加速,达到7Hz闭环控制
与 Fast-WAM 的区别
| 维度 | Fast-WAM | DreamZero |
|---|---|---|
| 核心问题 | 测试时是否需要想象未来? | 世界动作模型能否作为零样本策略? |
| 方法 | 去掉测试时未来生成,保留训练时视频共训练 | 联合建模视频和动作,自回归生成 |
| 模型规模 | 基于 Wan2.1-5B 视频扩散模型 | 14B参数自回归扩散变换器 |
| 优化重点 | 推理速度提升4倍 | 推理速度提升38倍,实时控制 |
| 泛化能力 | 在训练任务上加速 | 零样本泛化到全新任务 |
详细模型结构、训练与推理
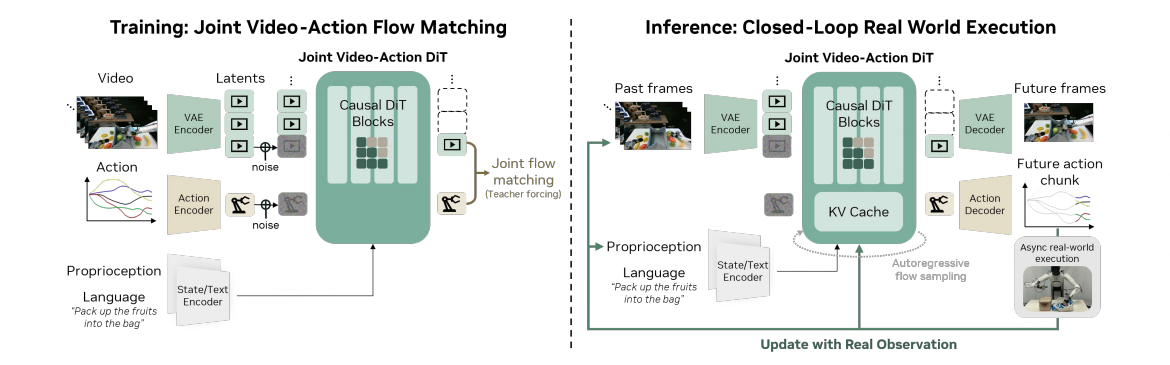
1. 模型结构 (Model Architecture)
DreamZero 是一个拥有 140 亿参数(14B)的自回归世界动作模型(World Action Model, WAM)。它建立在预训练的视频扩散主干网络之上,旨在通过同时预测未来的视觉状态和机器人动作来实现强大的泛化能力。
核心架构组件:
- 主干网络: 使用预训练的 Wan2.1-I2V-14B-480P 图像到视频扩散模型作为底座。
- 端到端设计: 不同于将视频预测和动作预测分开的模块化模型,DreamZero 是一个单一的端到端模型,通过共享的流匹配(Flow-matching)目标同时进行视频和动作的去噪。
- 自回归与分块: 模型以分块(Chunk-wise)的方式进行预测。每个块包含固定数量的潜在帧和对应的动作序列。这种自回归设计允许利用 KV 缓存(KV Cache) 来提高推理速度并支持长上下文。
- 特定编码器与解码器:
- 编码器: 包括视觉 VAE 编码器、文本编码器(处理指令)和状态编码器(处理本体感觉)。
- 解码器: 包含视频 VAE 解码器和动作解码器,分别从 DiT 提取的潜在表示中恢复未来视频帧和动作块。
2. 模型输入 (Inputs)
模型在每个推理步骤中接收以下三种主要模态的信息作为条件:
- 视觉观察 (Visual Context): 包括当前帧和过去的历史观察序列($o_{0:l}$),通过 VAE 编码为潜在向量。
- 语言指令 (Language Instructions): 自然语言形式的任务描述($c$),由预训练的文本编码器处理。
- 本体感觉状态 (Proprioceptive State): 机器人的内部状态信息($q_l$),如关节位置等,通过状态编码器输入。
3. 模型输出 (Outputs)
DreamZero 在每个预测周期内联合输出未来一段时间(视野范围内)的两种数据:
- 未来视频帧 (Future Video Frames): 对世界演化的视觉预测($o_{l:l+H}$)。这作为一种"隐式视觉规划器",指导动作的生成。
- 连续动作块 (Continuous Action Chunk): 机器人执行任务所需的电机控制指令序列($a_{l:l+H}$)。
核心设计优势
- 闭环执行: 推理时,模型生成的未来帧会被真实的地面观测事实(Ground-truth)替换,并更新到 KV 缓存中,从而消除了自回归生成中常见的误差累积问题。
- 实时控制: 通过系统级优化(如 CFG 并行、DiT 缓存和量化)以及 DreamZero-Flash 算法,该模型在 14B 规模下能实现 7Hz 的实时闭环控制。
关键创新
DreamZero 的核心洞察是:通过大规模预训练视频-动作联合建模,世界动作模型可以继承互联网规模视频数据中的丰富物理先验,从而实现对新任务的零样本泛化。这与传统 VLA 模型需要任务特定数据形成鲜明对比。
实验亮点
- 在 AgiBot G1 和 Franka 机器人上验证
- 在 22 个不同环境中收集 500 小时多样化数据
- 在从未见过的任务上达到 62.2% 平均任务进度(基线 VLA 仅 27.4%)
- 支持从人类视频或其他机器人进行跨具身迁移
本文基于论文原文和官方项目主页内容整理,所有事实性结论均标注来源。
Comments (0)
Please sign in to leave a comment.